_[논문리뷰] A survey Of learning-Based control of robotic visual servoing systems
Journal of the Franklin Institute, 2022. paper
Jinhui Wu, Zhehao Jin, Andong Liu, Li Yu, Fuwen Yang
해당 논문은 VS 시스템에서 사용되는 MPC와 결합된 SOTA learning-based algorithms을 소개한다. VS의 modeling 방법과 control 방법이 소개된다. 여기에 NN based 알고리즘, RL based 알고리즘이 도입되는 것의 장점이 소개된다.
Abstract
현대 robotics system의 주요 difficulty와 challenge는 robot에게 어떻게 self-learning과 self-decision-making ability를 주는가에 초점을 맞추고 있다. visual servoing control 전략은 vision을 통해 환경을 인지하기 위한 robotic system의 중요한 전략이다. vision은 새로운 robotic system을 더 복잡한 작업환경에서 더 복잡한 task를 완료하도록 안내할 수 있다. 이 연구는 sota learning based algorithm, 특히 visual servoing system에서 사용되는 MPC와 결합된, 을 설명하는 것, 그리고 몇가지 선도적이고 발전된, 몇가지 numerical simulation을 수행하는 reference를 제공하는 것이 목적이다. visual servo의 일반적인 modeling method와 robotic visual servoing system에 전통적인 control strategy의 영향이 소개되었다. NN based algorithm과 RL based algorithm을 system에 도입하는 것에 대한 장점이 논의되었다. 최종적으로, 기존의 연구 진행과 reference에 따라, 향후 robotic visual servoing system의 방향이 요약되고 전망되었다.
1. Introduction
로보틱스의 빠른 발전에 의해, 로봇은 의학적인 치료와 해양 작업과 같은 복잡한 task를 완료하기 위해 복잡해지는 것이 요구된다. 로보틱스 시스템에서 흔히 사용되는 센서는 ultrasonic, laser, gyroscope(angular velocity) 등이다. 그러나 이런 전통적인 센서들만이 로봇이 그런 복잡한 task를 완료하도록 유도하는 툴이라면, 전통적인 측정은 불출분한 정보만들 얻을 수 있고, 구조화되고 변하지 않는 환경에 적합하기때문에 performance는 악화되거나 task가 실패할 것이다.
vision sensor는 거리, 색깔 및 객체의 다른 특성을 측정할 수 있는 non-contact, low-cost 센서이다. 시각정보의 diversity와 readability는 점진적으로 로봇 시스템의 필수적인 부분이 되고 있다. computer vision의 다양한 알고리즘이 언급된다. 이것들은 로보틱스 전문가에게 필수적인 tool을 지원한다 그들이 vision sensor를 완전히 사용할 수 있게 만들기 위해서. 한편, visual servoing system에 대한 3가지 유익한 연구가 Hutchinson and Chaumette에 의해 출판되었다. 이것은 많은 학자들에게 로봇 visual servoing system에 대한 심층 연구에 관심을 기울이도록 영감을 주었다.
최근 몇년간, 지능은 visual servoing system의 필수적인 특징이 되었다. 그것이 구조화되지않은 환경에서 복잡한 task를 완료하도록 로봇의 능력을 향상시킬 수 있기 때문이다. 그러나 우리가 알기로, visual servoing system에서 learning based control을 conclude한 연구는 거의 없다. 그 gap(필수적인 특징인 반면 완료된 연구가 없다는 점)가 visual servoing에서 최신 learning based method의 application, 최신 learning based method와 전통적인 control method사이의 차이점과 관계를 요약하기 위한 survey paper의 결핍에 주로 영향을 미쳤다. 우리 survey에서, 우리는 위에 언급한 gap을 채우는 것을 목표로 한다 상응하는 reference와 learning based visual servoing method에 대한 analysis를 통해. 우리 survey의 메인 코어와 중요한 novelty는 threefold이다.
- 이 survey는 다양한 전통적인 control과 visual servoing system에 사용된 learning based control을 구조적으로 요약한다. 이 survey를 읽음으로써, 독자들은 세가지 측면에서 learning-based visual servoing systems의 연구 진척을 빠르게 이해할 수 있다. 1) controller의 설계, 2) model learning, 3) 최적화 문제-solving. 이 survey의 분석과 reference에 따라, 그들은 미지의 깊이 정보, parametric uncertainty, nonlinear optimization, self-decision에 대한 문제를 다루는 특정한 방법을 찾을 수 있다.
- 이 survey는 전통적인 control과 visual servoing systems에 사용된 learning-based control의 장단점을 분석한다. 이 survey를 통해 우리는 학제간의 학자를 위한 아이디어를 제공하고 그들이 safety와 로봇 visual servoing 시스템의 intelligence 문제의 균형을 맞출 수 있도록 전통적인 control과 learning-based control method의 장점을 결합하도록 고무시키기를 희망한다.
- 전통적인 control 방법과 지능적인 learning method(adaptive NN, safe control, model free MPC)의 장점을 완전히 처리할 수 있는 3가지 유망한 방법론이 제안되었다. 또한 2가지 유망하고 실질적인 시나리오(multi-robot cooperation and human-robot collaboration)가 향후 방향으로 주어진다. 제안된 5가지 방향은 로봇 visual servoing control method를 부흥시키고 application field를 확장시키는 것에 대해 희망적이다.
2. Visual servoing system
visual servoing system은 로봇이 vision sensor로부터 취득된 이미지 정보를 사용할 수 있도록 허락하는 시스템의 한 종류이다. 이 기술은 복접한 환경에서 시각정보에 대한 인지능력의 완전한 사용을 가능하게 하고, 로보틱스 시스템을 unknown environment로 확장시킨다.
시각정보의 사용에 대한 각각 다른 관점에 따르면, visual servo는 다음과 같이 나눠질 수 있다: image-based visual servo(IBVS), position-based visual servo(PBVS), hybrid visual servo(HVS). IBVS은 기본적으로 feature point의 world좌표를 pixel plane으로 변환하는 camera의 projection관계를 사용한다. 이 modeling 방법은 2D visual servo로도 알려져있다 이것은 직접적으로 pixel plane내의 robot을 제어할 수도 있기 때문에. 이 특성때문에, 이것은 카메라와 환경 사이의 position에 대한 독립성, 카메라의 modeling distortion에 맞서는 내재된 강건성, 그리고 소량의 계산을 갖는다. 그러나 단점은 깊이 정보가 modeling 과정에서 소실되고, image jacobian matrix가 강하게 coupling될 것이라는 것이다. PBVS은 3D visual servo로도 알려져있으며, 객체에 상대적인 카메라의 pose를 사용하여 error model을 만드는 방법이다. 이것은 이미지 character와 카메라와 객체의 기하학적 model을 통해 로봇의 pose를 추정할 수 있다. 추정된 pose는 servo task를 완료하기 위해 사용된다. PBVS의 장점은 3D 정보의 물리적인 의미가 명확하다는 것이다. 이것은 pose가 추정되면 visual servoing 문제를 풀기위해 전문가가 일반적인 로봇 시스템으로써 같은 방법을 사용할 수 있다는 것을 의미한다. PBVS의 servo efficiency는 추정의 정확정에 의존한다는 것은 명확하다. 이것은 PBVS의 주요 문제점이다. IBVS와 PBVS을 결합한 HVS은 위의 단점들을 해결하기 위해 제안되었다. 이 방법이 효율적이지만, HVS이 *homography matrix를 푸는 것이 필수적이다. 이것은 보통 single image-based나 position-based VS보다 더 복잡하다.
\[s[x^{'}\ y^{'}\ 1]^T = H[x\ y\ 1]^T\]homography matrix: homography는 2가지 평면사이의 projective transformation이다. image에 대한 2가지 평면 projection사이의 mapping을 설명하는 행렬이라고도 할 수 있다. 다른 말로, homography는 2가지 image사이의 상대운동을 묘사하는 간단한 image transformation이다.
homography matrix(H)는 wide scene내의 점과 narrow scene내의 점 사이에서 correspondence를 만드는 것으로 추정될 수 있다.
다른 분류는 카메라의 position에 관련된다. 비유적으로, visual servoing system에서 로봇은 손처럼 행동하는 반변, 카메라는 눈처럼 행동한다. hand-eye relationship에 기반할 때, visual servoing system은 2개의 카메라 configuration을 갖는다: eye-in-hand 시스템과 eye-to-hand 시스템. eye-in-hand 시스템에서, 카메라는 robot에 mount되어있고 거기에는 알려진, 그리고 일정한 카메라의 pose와 로봇의 pose사이의 관계가 있다. 이 시스템은 일부지만 정확한 feature의 view를 갖는다. eye-in-hand 시스템은 space manipulator를 위한 visual tracking control문제를 해결히기 위해 이용된다. adaptive parameter에 기반할 때, eye-in-hand 시스템은 tubular 로봇에 적용된다. 이것은 전체 시스템이 closed loop를 형성하고 외과수술중에 tubular 로봇의 안정성을 향상시키도록 만든다. 반면, 카메라가 로봇과 전체 workspace를 관찰하기 위해 로봇 위에 고정되어 있을 때, 이 종류의 시스템은 eye-to-hand 시스템이라고 부른다. 여기서 눈은 전반적이지만 거칠지않은 view를 갖는다. Liang and Wang은 wheeled mobile robot의 position contol을 완료하기 위한 adaptive image-based controller와 3가지 feature point를 갖는 uncalibrated fixed 카메라의 문제를 다루기위한 독창적인 model을 제안한다. 전반적으로, eye-in-hand 시스템은 전체 workspace와 상호작용할 수 없고, globally fixed camera(eye-to-hand 시스템)는 높은 유연성과 정확성이 필요한 task에 능숙하지 않다. 그래서 복잡한 작업은 더이상 단일 camera type에 한정되지 않는다. 예를 들어, hybrid framework와 terminal sliding mode control는 exponential regulation을 달성하는 것 대신에 finite harvesting time을 보장하기위해서 robotic fruit harvester에서 조합된다.
3. Classical control schemes
이 섹션은 다양한 전통적인 control scheme, 로봇 visual servoing 시스템에서 사용되는 그런 전략의 장단점을 소개하는 것을 목적으로 한다.
우선, 다음의 일반적인 모델이 로봇 visual servoing 시스템을 나타내기 위해 주어진다.
\[x(k+1) = f(x(k)) + g(x(k))u(k) - (1)\]subject to constraints
\[f_1(x) <= 0 - (2), f_2(x) >= 0 - (3), f_3(x) = 0 - (4)\]여기서 x(k), u(k)는 state variable과 system input을 의미한다. 그들은 카메라 parameter, 로봇 pose와 velocity와 관련있다. 로봇 visual servoing 시스템에 대해, constaint(2)는 보통 actuator saturation로 유발된 input constraint, visibility constaint 등으로 나타난다. constraint(3)는 물리적인 actuator, 장애물 회피 등의 최소 작동 threshold를 나타낸다. constraint(4)는 *nonholonomic constraint, visual geometric constraint 등을 나타낸다. 위의 시스템에 기반할 때, 다음과 같이 이런 문제를 풀기위한 많은 방법이 있다.
nonholonomic system: physical system whose state depends on the path taken in order to achieve it. nonholonomic constraint: 특정 움직임에 대해, 시스템이 제어를 할 수 없는 constraint
3.1. Adaptive control
adaptive control 법칙은 일반적으로 nominal control part와 auxiliary adaptive part를 포함한다. adaptive control은 모델의 uncertainty를 교정하기 위해 표준적인 processing method 집합을 갖고, 모델의 stability는 Lyapunov method를 통해 쉽게 증명할 수 있다. unknown image velocity, parametric uncertainty, time-varying depth를 갖는 manipulaor 시스템의 closed double-loop control 방법을 고려할 때, passive와 nonlinear observer를 결합한 two adaptive control 방법이 kinematics와 dynamics loop를 분리하기 위해서 제안되었다. servo 과정동안 feature point가 소실되는 것을 피하기위해, 모바일 로봇을 control하기 위한 constant parameter를 사용하는 대신, image jacobian matrix의 mixture parameter를 adaptive하게 조정하기위해 RL이 결합된 adaptive control접근법이 제안되었다. 이 연구의 실험은 제안된 adaptive controller가 feature point 소실현상을 처리할 뿐만아니라 제안된 효과적인 Q-learning algorithm을 통해 더 빠른 convergence를 보인다. 로봇은 복잡한 작업환경에서 인간이나 환경과 상호작용하는 것은 필수적이라고 알려져있다. soft manipulator 시스템의 경우, 이러한 상호작용은 시스템의 parameter를 바꾼다. Wang et al는 상호작용의 부정적효과를 극복하기 위해 piecewice-constant curvature kinematic에 기반한 adaptive visual servo controller를 제안한다. 그러나 adaptive control method는 단점을 갖고 있다. robotic visual servo의 현실적인 시나리오에서, 각 시나리오에 맞게 adaptive parameters를 조정하는 것은 어렵다.
3.2. Sliding model control
sliding mode control은 상응하는 controller를 설계함으로써 시스템의 state를 sliding surface로 유도할 수 있다. 그리고 그 후에 시스템의 origin에 도달한다. 시스템이 sliding surface에 도달하면, 그 시스템은 내재적으로 disturbance에 강건하다. featureless object의 motion tracking을 위해, Parsaour et al에 의해 Kernel measurement가 visual servo와 결합되었다. tracking error를 제거하고 stability region을 확대하기 위해서 kernel-based sliding mode control이 PI-type sliding surface를 갖고 제안되었다. robot rebeting을 위한 PBVS에 대해, Zhao et al.은 positioning process를 path-following과 spot positioning으로 분리했다. 그리고 sliding mode control을 switch하는 것을 제안한다. 엄밀하게는 2가지 단계에 대해, varying parameter-linear sliding surface와 second-order sliding surface가 error와 external disturbance에 대항하여 정확한 task를 달성하기 위해서 각각 제안된다. Liu et al는 HVS framework에서 super-twisting sliding mode control의 설계를 발전시켰다. 이는 rivet-in-hole insertion task 동안 시스템이 desired pose로 exponentially converge하게 할수 있다. 일반적인 sliding mode controller의 control input은 discontinuous하고, sliding surface의 design은 휴리스틱하다. 이는 sliding mode surface에서 시스템의 진동을 유발하고 sliding mode control의 주요 단점으로 이끌 수 있다.
3.3 Fuzzy control
fuzzy control은 robotic visual servoing system의 variable들의 관계를 설명하기위해 사용된다. fuzzy control 전략은 정확한 모델없이도 설계될 수 있다. Wang et al는 무인 surface vehicle을 desired pose로 유도하기위한 finite-time velocity observer와 통합된 dynamics-level fuzzy homography-based visual servoing 방법을 설계했다. 여기서 측정할 수 없는 poses, velocities, depth information, 시간에 따라 inertia가 변하는 복잡한 dynamics model에 대한 보상을 위해 adaptive fuzzy dynamics approximator가 제안된다. Shi et al는 wheeled mobile robot의 효험을 향상시킬 수 있는 decoupled image-based visual servoing 전략의 framework하에서 fuzzy adaptive method를 제안한다. 전통적인 IBVS에서 보여주는 1개의 servo gain을 활용하는 것 대신, 2개의 분리된 servo gain은 각각 translation과 rotation을 control하기 위해 사용된다. 이 reference의 독창성은 빠른 convergence를 갖고 adaptive하게 mixure parameter를 조정하기 위해서 fuzzy method와 함께 개선된 Q-learning을 사용한 것이다. 7-DOF manipulator system의 eye-in-hand visual servo에 대해서는, controller parameter를 dynamical하게 tunning하는 동안 desired position을 track하기위해서 Takagi-Sugeno (T-S) fuzzy framework가 PD controller에 통합되었다. fuzzy control의 주요 단점은 상응하는 controller가 엄밀하지않은 수학적인 규칙을 갖는 fuzzy rules의 선택에 의존한다는 것이다.
3.4. Iterative learning control
Iterative learning control (ILC)은 반복적인 motion 특성을 갖는 제어대상에 적합하고, 유한한 time interval안에 tracking task를 완료할 수 있다. 이것은 trials을 통해 시스템을 control할 수 있고, 시스템 output 정보의 주어진 trajectory로부터의 편차를 이용하여 불만족스러은 control signal을 교정한다. 이것의 반복적인 특성때문에, 학자들은 산업용로봇시스템, 열차정지control, discrete system control같은 다양한 시스템에 ILC를 사용한다. ILC의 주요 단점은 각 iteration process에 대해 initial state가 항상 같다고 가정한다는 것이다. visual servoing systems의 내용에서, 시스템을 control하기 위해 ILC를 쓰는 것이 제안되는 reference는 거의 없다 image plane에서 초기 가정을 보장하는 것이 어렵기 때문에. 우리가 아는 바로는, ILC control 방법은 오직 demonstration task에서 vision-guided learning을 위한 목적으로 사용되었다. demonstration task에서 manipulator가 반복적인 방식으로 engineer로부터 trajectory를 학습하는 것을 돕기위해 visual feedback 정보가 사용된다. 임의의 초기 이미지 position에서 visual servoing systems을 직접적으로 control하기위해 ILC를 사용하는 방법은 open queastion이다.
3.5. Model predictive control
receding horizon control으로도 알려진 Model predictive control은 constraints를 명시적으로 처리할 수 있다. 이는 다중 constraint를 가진 robotic visual servoing systems에 매우 적합하다. 시스템 1에 대한 MPC performance index는 다음과 같다.
\[J = \sum_{k=0}^{N-1} l(x(k) , u(k)) + l_{N}\]l(x(k) , u(k))는 0부터 N-1까지의 term의 loss function이고, l_{N}은 MPC에 대한 closed-loop system의 stability를 보장하기 위한 미래의 infinite horizon을 추정하는 terminal term이다. performance index를 최소화함으로써, MPC optimization을 도출할 수 있다. 요컨데, robotic visual servo을 위한 MPC controller의 설계는 optimization problem으로 변환될 수 있다. Jacobian matrix, camera parameters, 복잡한 dynamics와 robotic visual servoing 시스템의 uncertainties가 결합되어 있기때문에 optimization problem은 일반적으로 nonlinear form을 갖는다. 이 현상은 nonlinear MPC(NMPC)의 중요성으로 이끈다. online solving optimization problem의 방법에 따라, nonlinear MPC는 2가지 group으로 나뉠 수 있다.
- linear MPC controller을 사용하고, nonlinearity에 의한 영향을 보상하기위해 다른 기술과 결합하는 그룹.
- 직접적으로 NMPC optimization problem을 푸는 그룹.
첫번째 group에서, 연구자들은 시스템을 변환하기위해 보통 선형화 기술을 사용한다. 예를들어 equilibrium point 근처의 nonholonomic mobile robots 시스템을 선형화함으로써, linear model이 유도되고 camera와 inertial sensor의 사라진 측정값을 처리하기위해서 optimal MPC estimator가 설계된다. 같은 선형화를 갖고, mobile robots이 visual point stabilization과 visual trajectory tracking을 각각 완수하도록 유도하기위해서 robust least square method에 기반한 robust MPC controller가 제안된다. IBVS을 linear time-invariant시스템으로 변환하기 위해서 Tensor-product (TP) 모델 변환 방법이 구현되었고, 6DOF manipulator를 위해서 quasi-min-max MPC controller가 설계되었다. online navigation을 위해서 Taylor series 근사가 사용된다. 시스템을 선형화하는 모든 MPC methods는 적절한 nominal model의 선택에 크게 의존한다. 이런 방법들로 얻어진 linear MPC controllers는 큰 model mismatch가 발생하기때문에 실제 시나리오와 멀리 떨어져있다.
두번째 group에서, 설계자가 model을 선형화하는 것은 필수가 아니다. 얻어진 NMPC controller는 simulation에서 로봇 실험으로 migration하는데 있어서 실용적이고 도움이된다. 지금까지, NMPC and robotic visual servoing systems을 성공적으로 결합한 학자는 거의 없다. Iterative linear quadratic Gaussian(iLQG)이 computational delay를 가진 four-wheeled nonholonomic system에서 사용되었다. local linearization을 우회하는 또 다른 유망한 solution은 Lyapunov-based MPC (LMPC)이다. Shen and Shi는 LMPC을 autonomous underwater vehicle systems에 도입한다. LMPC controller는 nonlinear underwater vehicle 시스템이 trajectory tracking task를 완수하도록 유도할 수 있다. 게다가 recursive feasibility, closed-loop stability, attractive region의 존재가 입증되었다. 하지만 이 방법의 설계는 Lyapunov function에 강한 correlation을 갖고 있다. Lyapunov function의 선택이 사소하지 않다는 것은 control community의 모든 전문가들에게 알려져있다. Heshmati et al.는 visual tracking tasks를 완수하기위해 self-triggered NMPC와 PBVS를 결합한다. trigger condition은 이 control scheme의 performance에 큰 영향을 미칠 수 있다.
명심해라. MPC는 이 subsection에서 고전적인 control 방법으로 소개된다. 학자들이 이 control 방법에 주의를 기울이는 이유는, MPC가 current state를 사용할 수 있고 finite horizons내의 future state를 model할 수 있기 떄문이다. 이 특성은 미래 states를 예측하고 변하는 환경의 영향을 줄이는 AI 알고리즘과 유사하다. 게다가, MPC의 본질은 constrained 최적화 문제를 푸는 것이다. 이것도 다양한 지능형 알고리즘과 닮았다. 이 2가지 특성이 MPC가 learning-based 알고리즘과 결합하는 것이 적합하게 한다. 이것의 적합성을 설명하기 위해서, 이 subsection에서 고전적인 MPC와 그에 상응하는 VS 시스템에서의 개발을 소개하고, 이후 Learning-based MPC를 소개할 것이다.
Remark 1:
robust control은 controller의 behavior로 여겨질 수 있기 때문에, 이 논문에서는 robust control를 typical control method로 간주하지 않는다. 이 remark에서는 간단하게 VS시스템에서 robust control 전략을 논한다. 예를 들어, 야외환경에서 target tracking task문제를 다룬 Zhang et al.는 PBVS 방법의 원칙에 대한 robust compensator를 제안한다. 이는 nonlinearities, couplings, and parametric uncertainties를 처리하는 능력을 높힌다. Mehta et al.는 7-DOF manipulator시스템에 대해, 돌풍과 fruit detachment force에 의해 발생하는 unknown fruit > motion을 보상하기 위핸 robust visual servo controller를 소개한다. finite-time convergence와 시스템 stability는 Lyapunov theory에 의해 분석된다. yaw information없이 수직이착륙을 완수하는 목표를 갖고, Jabbari et al.는 unmanned aerial vehicle에 대한 robust IBVS control방법을 소개한다. 이 방법은 estimated velocities를 사용함으로써 unknown depth information에 강건하다. robust control이라는 의미에서, 최악의 경우에 대해 stability와 robustness을 보장되고, performance는 정량적으로 분석될 수 있고 최적화될 수 있다고 결론난다. 그러나, robust controllers에서 최악의 경우가 고려되기때문에 이 방법은 너무 보수적이고 robust controller의 gain은 항상 크다. 이는 심각한 actuator손실의 원인이 된다.
3.6. Example discussion of classical control methods
여러 control방법의 효과를 명확하게 보이기 위해서, 우리는 간단하게 다음과같은 IBVS시스템의 수치 시뮬레이션을 제공한다.
\[\dot{X} = L(x,y,z)u - (8)\]여기서 normalized 이미지 가로좌표 x, normalized 이미지 세로좌표 y를 갖는 state vector X는 \(X = [x, y]^T\) 이다. image Jacobian matrix L은 다음과 같다. 여기서 depth information z, system input u는 \(u = [v, ω]^T\), velocity v, angular velocity ω이다. // 즉, system input u는 spatial velocity.
\[L(x,y,z)= \begin{bmatrix} \frac{x}{z}& -(1+x^2) \\ \frac{y}{z}& -xy\\ \end{bmatrix}\]이 시뮬레이션의 목적은 position x,y를 desired position \(x^*, y^*\)에 수렴하게 하는 것이다.
다음의 다양한 control method는,
- MPC parameters: weight matrices \(Q = 10I , R = 0.1I\), prediction steps N = 20
- Adaptive controller(AC) : control gain \(k_1 = 5 , k_2 = 1 , k_3 = 0.2, k_4 = 0.2\)
- Sliding mode controller(SMC): sliding surface \(S = tanh(x−x^*)\)
- fuzzy controller:
with the fuzzy parameter \(β\_{fuzzy}\)
다음 figure에 나타낸다.
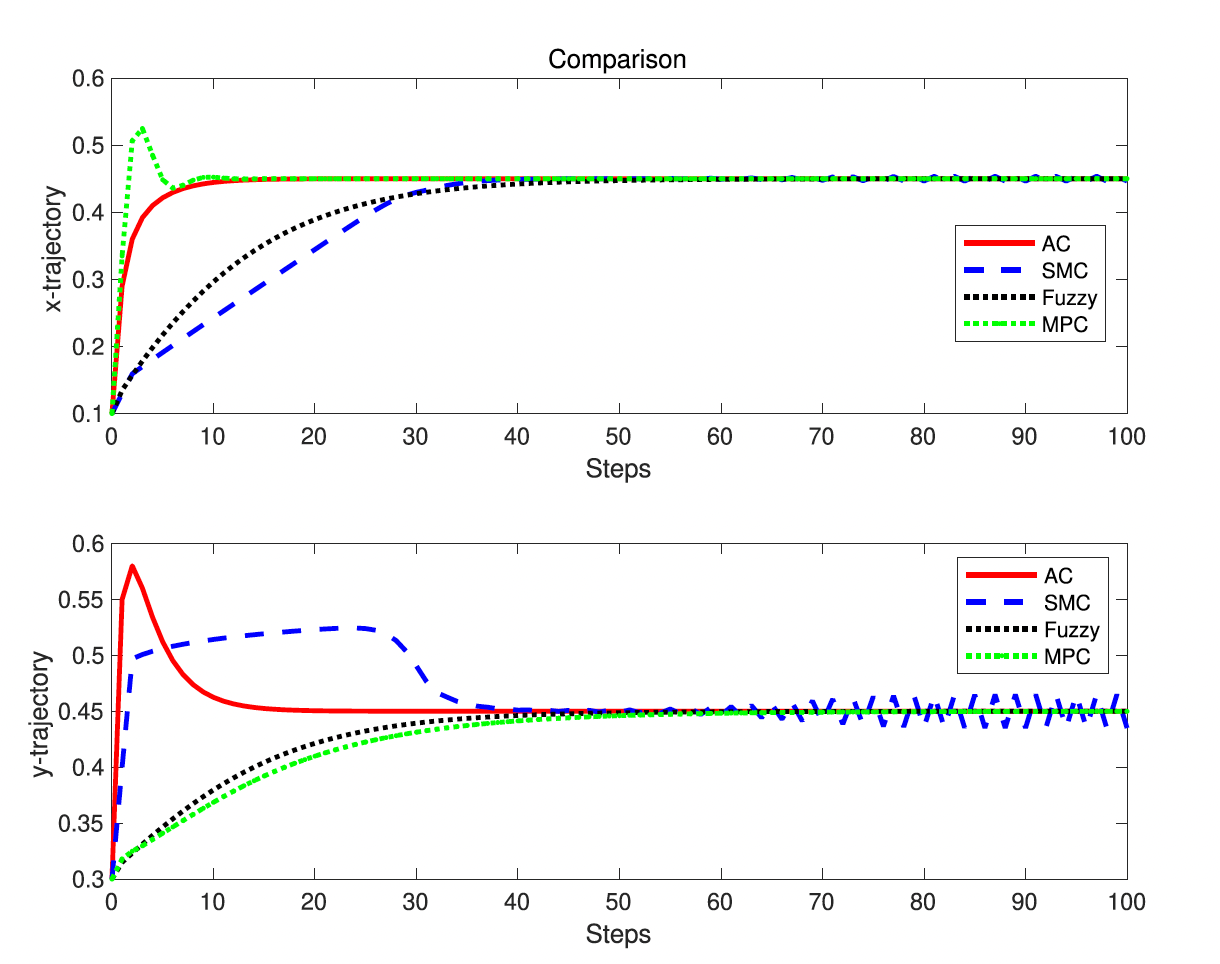
fig1. The results of classical methods with initial state (0.1,0.3), desired state (0.45,0.45) and sampling time 0.1s
fig1은 모든 controll 방법이 시스템을 desired image position으로 수렴하도록 만들 수 있다는 것을 보여준다. 그러나 각 control 방법은 단점을 갖는다. 예를 들어, SMC는 zero근처에서 chattering 한다. 나머지 방법들은 부드럽게 수렴하지만, parameter를 tuning하기 어렵다. 명심해라. 이 paper에서 간단한 VS시스템을 고려하고 있고 여기서 모든 방법은 비슷하고 효율적으로 작동한다. 특정 VS 문제에 적용된 각 control 방법과 세부사항은 위에서 언급한 references를 참고해라.
4. Neural networks
neural network(NN)은 생물학 분야에서 기원했다. 사람 뇌의 메커니즘을 연구할 때, 생물학자들은 neurons이 전기신호와 network를 통해 정보를 전달한다는 것을 알았다. 인간의 뇌가 다양한 복잡한 task를 수행할 수 있다는 것이 NN의 존재이다. computer science의 발전에 따라, 그런 메커니즘은 caculation unit에 도입되었다. 즉 calculation unit을 연결하고, NN을 구축하고, 컴퓨터의 점점 강해지는 연산능력으로 NN을 train하고, 마침내 expected value를 출력한다. 최근에 점점 많은 연구자들이 robot VS시스템에서 NN을 고전적인 control scheme에 적용하고 있다 특히 MPC에. 다음 내용에서, NN의 다른 기능에 따라 2가지 다른 분류가 설명된다. robot VS시스템에서 servo accuracy(1)는 modeling process와 관련된다. 시스템이 friction, gravity, load, visual vibration, visual failure, 다른 환경적인 uncertainties와 disturbances에 영향을 받기 때문이다. 반면 servo rapidity(2)는 online 최적화와 image recognition의 효능에 의존한다. 다음과 같이 2가지 문제가 고려된다.
- 어떻게 정확한 모델을 만드는가.
- 어떻게 큰 계산부담을 덜어주는가.
4.1. Model learning
NN을 사용해서 model을 fit하는 것은 로봇 VS에서 research hotspot이다. 이 경우, 무작위로 수행되는 시스템에 의해 얻어진 첫번째 data set은training set과 the test set으로 나뉜다. traing set을 이용한 traing과 test set에서 testing 이후, NN은 기존의 robot visual servo model을 대체할 수 있다. 다음 내용에서 robot VS시스템에 대해 2가지 주요 issue가 고려된다.
4.1.1. Unknown depth information
IBVS를 사용할 때 주요 issue는 depth information가 사라진다는 것이다. 이전에 했던 논의처럼, IBVS는 pixel정보를 이용해서 robot을 control한다. 따라서 식(1)은 다음과 같이 다시 쓸 수 있다. (x(k) -> p(k),z(k)) \(p(k+1) = f(p(k),z(k))+g(p(k),z(k))u(k) - (5)\)
여기서 \(p(k)=[p_x(k),p_y(k)]^T\) , \(p_x(k), p_y(k)\) 는 각각 pixel의 가로좌표, 세로좌표이다.
\(z(k)\)는 카메라에서 feature의 깊이를 측정한 depth information을 나타낸다. IBVS는 2D model이기 때문에, \(z(k)\)는 내재적으로 unknown이다. 그러므로 우리는 control의 accuracy를 위해서 depth information를 추정해야한다. depth information을 추정하기위한 방법으로는 observer,Kalman filter등이 있다. 간소화된 image Jacobian matrix은 일반화된 image Jacobian matrix으로부터 depth information를 decoupling함으로써 제안된다. 그러나 제안된 matrix는 결국 경험적으로 평가되고 낮은 일반성을 갖는다. Calise et al.가 nonlinear function을 fitting하는 NN의 feasibility와 convergence를 증명한 이후, 이 ability는 depth information을 추정하기위해 사용된다. radial basis function neural network가 depth information을 추정하기위해 사용되고, proportional-integral(PI) control과 결합하여 dual manipulator의 trajectory tracking task가 완료된다. depth information과 coupling된 kinematic model은 concurrent learning algorithm을 사용해서 만들어졌다. Kalman filter는 uncalibrated camera parameters와 depth information을 추정하기위해 사용되고, NN은 Kalman filter에 의해 발생한 error를 보상하기위해 사용된다.
4.1.2. Unknown dynamics and external disturbances
이전에 논의했던 것처럼, robotics VS시스템은 friction, gravity, complex unknown dynamics, visual failure and blurred vision이 존재한다. 이런 것들은 mechanism에 의해 만들어진 model을 실제 model에서 벗어나게 만들 수 있다. 그런 factor들을 고려할 때, 식(1)은 nominal(계획대로의) model \(f_n\) 학습될 \(f_{un}\) 부분으로 다음과 같이 다시 쓸 수 있다.
\[x(k+1) = f_n(x(k),u(k))+f_{un}(x(k),u(k),\Delta(k),d(k)) - (6)\]여기서 \(\Delta(k)\)는 uncertain model, \(d(k)\)는 bounded external disturbances를 의미한다.
\(f_{un}\)부분은 다음의 서술에 따라 NN에 의해서 fitting될 수 있다.
\[f_{un} = \hat{W}\phi(\hat{V}^T\eta)\]여기서 \(\eta\)는 \(f_{un}\)의 값을 결정할 수 있는 가능한 각 variable을 포함하고 있는 decision variable의 vector이다.
그리고 이 다수의 vector들은 NN의 input을 의미한다.\(\hat{W}, \hat{V}\)는 둘다 NN의 weight matrix이다. 함수 \(\phi(·)\)는 activation function을 의미한다. 이러한 NN을 토대로, 식(6)은 다음과 같이 유도된다.
단일의 hidden layer NN과 NMPC(nonlinear)는 underwater vehicle의 dynamic positioning task를 완수하기위해 사용된다. 여기서 NMPC는 kinematic level의 dynamic reference speed를 얻기위한 IBVS과 결합된다. 그리고 단일의 hidden layer NN은 dynamic의 model error를 추정하기위해 사용된다. unknown external nonlinear parameter는 radial basis function neural network를 사용해서 추정된다. 그리고 manipulator의 error가 adjustable origin의 neighborhood로 수렴하게 만들기위해서, NN based adaptive controller가 설계된다. Visibility constraint과 dead-zone input이 추가로 고려된다.(참조논문참고) radial basis function neural network는 위의 relation을 추정하기위해서 image의 geometric model이나 manipulator의 kinematics와 dynamics model을 수립하지 않고 직접적으로 사용된다.
4.2. Optimization methods
위의 논의에 따라, model은 NN의 조합이후에 fitting된다고 간주할 수 있다. 이 가정하에, MPC는 constrained robotic VS시스템을 위한 매우 강력한 control전략이 된다. 이외에도 robotic VS시스템이 해당하는 MPC optimization 문제를 효과적으로 다룰 수 있는 방법을 찾는 것은 중요하다. NN은 필요한 정보를 fitting하는 것뿐아니라, MPC optimization problems의 최적해를 찾는 수단으로써 사용될 수도 있다. Xia and Wang은 input이 다음 general form에서 반복되는 경우, RNN을 framework로 제안했다.
\[u(k+1) = P_{\Omega}(u(k)−\alpha(Wu(k) + c))\]그럼 input은 다음 performance index에 따르는 최적값으로 수렴한다.
\[min \frac{1}{2}u(k)^TWu(k)+c^Tu(k)\]s.t. 식(1), 식(2), 식(3), 식(4).
여기서 W와 c는 각각 weight matrix, MPC performance index로부터 유도된 vector이다. \(\alpha\)는 learning rate, \(P_{\Omega}\)는 constraint와 관련된 saturation activation function이다. 이 theory에 기반해서, survey[66](참조논문참고)은 다양한 NN을 사용한 manipulator control을 자세히 서술한다. 여기서 Hopfield network, spiking neural network, echo state network와 dual network가 결론난다. primal dual neural network (PDNN)의 framework는 MATLAB/Simulink으로 build되고, 최종적인 hardware realization은 다양한 constraint를 가진 linear quadratic optimization problems를 풂으로써 달성된다. PDNN은 nonholonomic constraint, state constraints, input constraint를 갖는 MPC performance index를 최소화하기위해 사용되고, visual point stabilization에 대한 task와 wheel mobile robot을 위한 trajectory tracking이 완수된다.(참조논문참고)
Remark 2:
MPC의 response time과 computation time은 prediction steps, optimization methods and system dynamics에 의존하는 것으로 알려져있다. 중요한 점 중 하나는 각각의 optimization methods이 각각의 response time과 computation time를 야기한다는 것이다. 주류 중의 하나가 MPC optimization problems을 푸는 것이기 때문에, 이 survey에서 NN은 결론을 맺었고 computational complexity의 세부적인 분석은 참조논문을 참고한다.(참조논문참고) 이 문제는 많은 수학 이론을 포함하고있기 때문에, 이 survey의 범위를 벗어난다. 관심있는 독자는 optimization에 관한 textbook이나 reference를 참조바란다.(참조논문참고)
4.3. Example discussion of MPC
이 subsection에서 우리는 같은 VS시스템을 갖는 MPC의 model learning의 중요성에 대해 논한다. model learning의 효과를 보이기위해, 우리는 예를들어 시스템이 Gaussian distribution \(\mathit{N}∼(0,0.05)\)의 disturbance를 겪고 있다고 가정한다. 이 가정은 unknown parameters, external friction disturbance때문에 실제 적용과 일치한다는 점을 주목할 필요가 있다. 게다가 우리는 depth information를 추정하기위해 NN을 쓴다. simplicity를 위해 우리는 NN depth approximation의 결과만 준다. 여기서 우리는 training set과 testing set에서 peak points에서 확실한 gap이 있음에도 불구하고. mean square errors가 zero 근처로 수렴하는 것을 볼 수 있다. disturbance 추정의 결과를 주는 것 대신에, perturbed system 식 8이 VS point stabilization task를 수행해서 model learning없이 직접적으로 충격을 반영할 때 우리는 states의 trajectory와 Input을 Fig.3–5에 묘사한다. figures에서 볼 수 있듯이, real model (TrueMPC)에 의해 설계된 MPC는 완벽하게 perform할 수 있다. control effect는 TrueMPC과 gap이 있지만, NN estimation에 의해 설계된 MPC(NNMPC)는 더 나은 performance를 갖고 target point에 근접할 수 있다. nominal model만을 이용하는 MPC controller는 robot이 target point에서 끊임없이 oscillate하게 해서 VS point task는 완수될 수 없다. 위에 분석된 현상은 Fig.4,5에서 명확하게 나타난다. NNMPC, TrueMPC는 point (0.6,0.6)을 track할 수 있는 반면, model learning없는 MPC는 강하게 진동한다.
5. Reinforcement learning
RL은 이론적 기반이 Markov Decision Process인 알고리즘이다. RL은 environment와 interact함으로써 optimal decisions을 학습하는 intelligent알고리즘이다. Fig.6는 RL의 RL의 4가지 기본요소를 가리키는 block diagram을 보여준다.
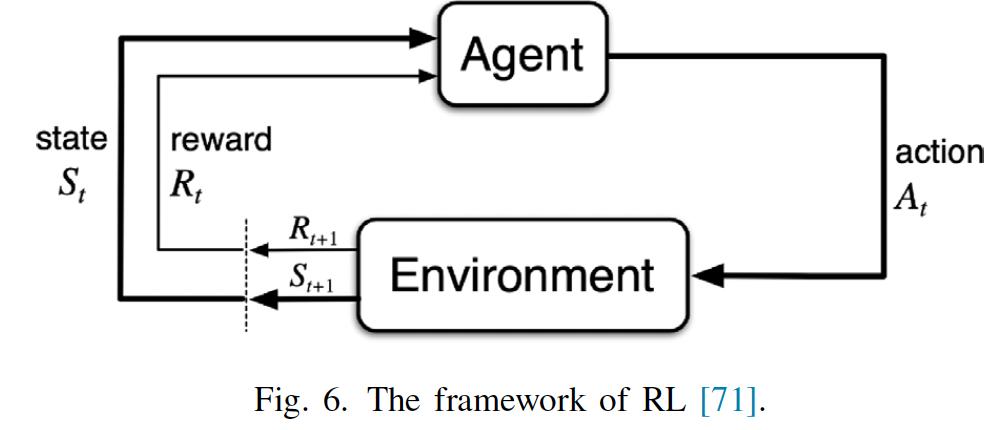
State set S: 이 set은 time t에 가능한 모든 state \(s_t\)를 포함한다. robotic VS시스템에 대해, state는 pixel 좌표(\(p_x(k) p_y(k)\)), depth information \(z(k)\) 등에 의해 구성될 수 있다.
Action set A: 이 set은 time t에 가능한 모든 action \(a_t\)를 포함한다. robotic VS시스템에 대해, action은 mobile robot에 대한 velocity와 angular velocity, manipulator에 대한 joint velocity 등을 표현할 수 있다.
Reward function \(R_t\): 이 function은 state \(s_t\)하에 action \(a_t\)를 취한 후 즉각적인 reward를 나타낸다. reward 설계의 합리성은 VS의 성공에 크게 영향을 미친다. 예를들어, servo가 성공(실패)할 때, positive(negative) reward가 주어질 수 있다.
State-transition probabilities p: p는 RL 환경을 설명하는 확률분포이다.
RL의 핵심은 다음의 Bellman equation form에 기반한 action-value function \(q(s_t, a_t)\)을 학습하는 것이다.
\[q(s t , a t ) = E s t+1 r + λmax a t+1 q ( s t+1 , a t+1 ) | s t , a t \]optimal value function \(v^∗(s_t,a_t)\)은 다음과 같이 정의된다.
\[q ∗(s t , a t ) = E s t+1 r + λmax a t+1 q ∗( s t+1 , a t+1 ) | s t , a t\]여기서 \(\lambda\)는 미래 valued function의 discount를 나타내고, \(\mathbb{E}s_{t+1}(·)\)는 state \(s_{t+1}\)의 state-transition probabilities하에 expected value이다. optimal action-value function에 따라, optimal policy \(π^∗(s_t)\) 는 다음과 같이 유도된다.
\[π^∗(s_t) = {arg}\ \underset{a_t}{max}\ {q^∗(s_t,a_t)}\]독자들은 포괄적인 이해를 위해 book [71]를 참조하는 것이 권장된다. environment의 model이 사용되는지아닌지에 따라 RL은 model-based RL(MBRL)과 model-free RL(MFRL)으로 분류될 수 있다. value function을 추정하는지 아닌지에 따라, RL은 value-based reinforcement learning (VBRL)과 policy-based reinforcement learning (PBRL)로 나뉠 수 있다. 4가지 주요 RL 알고리즘의 특성이 table1에 결론났다. RL의 설계는 exploration과 exploitation의 균형을 맞춰야함을 주의해라. 즉, RL 알고리즘은 optimal strategy와 environment를 exploring하는 것에 목적을 두는 random strategy사이의 trade-off(균형)를 만드는 것이 필요하다. optimal action이 각 step에서 취해질 때, environment를 exploring하는 것을 유지하는 것은 불가능하다. 반대로, robots이 모든 environment의 situation을 explore하는 것이 필요하다면, best policy는 각 step에서 보장될 수 없다. 이 상황에 기반해서, RL community의 전문가들은 policy를 ‘off-policy’와 ‘on-policy’로 분류한다. off-policy에서 environment를 explore하기 위해 사용되는 policy(explore)는 로봇에 의한 학습을 위해 사용되는 것(exploit)과 다르다. 반면 on-policy알고리즘은 같은 policy를 사용한다(환경탐사와 로봇학습에 대해).
table1. Summary of Four RL Algorithms
| Classification | property | Classical Methods and Representative Papers |
|---|---|---|
| MBRL | environment model p가 알려지거나 environment model이 data로부터 학습될 때 알고리즘이 optimal policy를 준다. 이것은 model learning이 끝나면 모델에 따라 직접적으로 strategy를 결정할 수 있다. 이는 알고리즘이 높은 data 효율성을 가졌음을 의미한다. | Guided Policy Search (GPS); Probabilistic Inference for Learning Control (PILCO) |
| MFRL | 이 종류의 알고리즘은 reward signal을 갖고 로봇을 train할 수 있고 environment model사용없이 상응하는 optimal strategy를 준다. learning의 결과는 직접적으로 기대값을 얻는 것이다. 이는 MBRL보다 더 직관적이다. | Q-learning; Deterministic Policy Gradient(DPG) |
| VBRL | 이 알고리즘은 optimal parameterized state value function \(v^∗(s,a|\hat{\theta})\)를 찾는 parameter \(\theta\)를 추정하기위해 다양한 추정 방법을 사용할 수 있다. 일반적으로, VBRL은 discrete control전략만 생성할 수 있고, 이는 continuous control에 적합하지않다. | Q-learning; Double Q-learning |
| PBRL | 이 종류의 알고리즘의 주된 목적은 policy를 \(\phi(s,a | \theta)\)로 parameterize하고 parameter \(\theta\)를 optimize하는 것이다. 이 알고리즘은 직접적으로 robot control strategy를 얻을 수 있고 control of manipulator같은 continuous control에 필요한 VS control에 더 적합하다. | DPG |
5.1. Classical reinforcement learning
Q-learning은 고전적인 model-free off-policy RL 알고리즘이다. 현재, 많은 학자들은 Q-learning을 robotic VS시스템에 도입했다. Wang et al.는 mobile manipulator를 특정 position으로 운전하고 물체를 grasp하기 위해서 Q-learning과 IBVS을 결합했다. feature points가 image의 safe area에 있을 때, 고전적인 image based control이 채택되고, feature points가 safe area로부터 벗어나있을 때, Q-learning controller가 전환된다. potential field function, navigation 등에 기반한 전통적인 방법에 비교해서 Q-learning은 online(agent가 환경과 상호작용)으로 control tasks에 자동적으로 적응한다는 것이 장점이다. 위에 언급한대로, image IBVS에서 Jacobian matrix는 control performance에 큰 영향을 갖고 있다. Shi et al.는 adaptively하게 image Jacobian matrix를 조정하기위해 image-based multi-agent system와 quadrotor system의 control에 Q-learning을 성공적으로 적용하였다. Q-learning은 복잡한 modeling과 servo gain의 선택문제를 해결하기위해 extreme learning machine과 결합된다.
5.2. Deep reinforcement learning
RL에 대해, value function과 policy에서 model과 parameter를 estimate하기위해 몇몇 estimation 방법을 사용하는 것은 불가피하다. 그러나 그런 알고리즘들은 비효율적이고 robot VS시스템에 적합하기 않다. 그것들은 서로다른 task에서 estimator의 parameter를 tune하기위해 time-consuming하기 때문이다. 그래서 많은 연구자들은 generalization을 향상시키기위해 DNN과 RL을 결합(이를 DRL이라고 한다.)하는데 노력하고 있다. DRL을 구현하는데는 3가지 문제점이 있다. 첫번째로, RL은 sparse, noisy and delayed reward signal을 받을 수 있어야한다. 두번째로 RL에서 data는 강한 correlation을 갖는다. 이는 NN의 training 기본 요구조건에 반대된다. 세번째로 RL에서 data distribution은 learning중에 변한다. 반면 DNN은 고정된 probability distribution을 요구한다. Mnih et al .가 처음으로 DRL의 수렴성을 증명하기위해 experience replay를 사용하고, RL의 convergence를 가속하기위해 DQN를 제안한 이후로, 많은 학자들은 robotic VS시스템에 DRL를 도입하는 것이 가능하다는 것을 알았다. 예를 들어, FOV에 문제를 갖고 있는 manipulator의 visual servo에 대한 point stabilization task가 DQN을 사용해서 해결되었다. DQN이 VBRL의 일종이기때문에, 이것은 discrete 문제만 다룰 수 있다. continuous problems을 풀기위해서, deep deterministic strategy gradient algorithm (DDPG)이 제안되었다. DDPG는 더나아가 quadrotor와 manipulator systems를 위한 visual servo에 적용되었다. 더나아가 DRL의 efficiency를 향상시키위한 PBRL와 VBRL의 장점의 결합을 위해서 actor-critic 알고리즘이 제안되고 시행되었다. 여기서 이 알고리즘의 critic network가 현재 policy에 의해 생성되는 value function을 estimate하고, 현재 policy를 평가한다. actor network는 optimal policy를 근사하기위해서 사용된다.
5.3. Reinforcement-learning-based model predictive control
control community의 관점에서, RL은 performance index를 최적화하고 control strategy를 계산하는 learning method로 설명될 수 있다. RL의 핵심은 infinite horizon내의 MPC의 최적화문제와 유사하다는 것이다. 구체적으로 MPC의 최적화문제는 다음과 같은 iterative form으로 서술될 수 있다.
\[u(k)= arg \underset{u}{min} l(x(k),u(k))+v(x(k+1)) - (9)\]where
\[v(x(k+1)) = \sum_{i=k+1}^{\infty} l(x(i+1),u(i+1))\]식(9)를 어떻게 풀 것인지, 즉 Hamilton Jacobi Bellman(HJB) equation를 어떻게 풀지는 가장 중요하고 어려운 문제라고 optimal control 학자들에게 알려져있다. optimal control관점에서 survey [89]는 RL을 adaptive dynamic programming(ADP)이며 HJB를 풀기위해 RL을 어떻게 사용하는지와 그런 문제에서 RL의 장점을 상세하게 설명한다. Xu et al.는 wheeled mobile robots에 대해서 NMPC에 의해 유도된 optimization problem을 풀고 trajectory tracking task를 완수하기위해서 actor-critic algorithm을 MPC와 결합했다. RL-based MPC는 이런 어려운 문제를 풀기위한 유망한 control 방법론이다.
HJB problems을 효과적으로 푸는것에 더해, RL-based MPC는 이론적인 model과 실제 model사이의 error를 학습함으로써 MPC가 robot 시스템을 더 정확하게 control할 수 있도록 도울 수 있다. Koryakovskiiy et al.는 humanoid robot의 복잡한 dynamics를 nominal part와 uncertain part로 나눈다. 여기서 NMPC는 deterministic policy gradient(DPG)가 uncertain part를 estimate하고 이 part의 영향을 보상하기위해 사용되는 동안 stability를 보장하기 위해서 사용된다. 게다가 RL은 적응적으로 MPC의 가중행렬을 조정할 수 있다. 이는 시스템의 stability를 보장할 뿐아니라, robot VS시스템의 servo efficiency를 높인다.
incremental Q-learning은 NMPC의 가중행렬을 조정하기위해 사용되고, 얻어진 optimal controller는 quadrotor가 trajectory tracking을 효과적으로 완수하도록 도울 수 있다.
NMPC의 가중행렬을 조정하기 위한 finite action-set learning automata (FALA)이라는 RL과 제안된 FALA-based MPC이 trajectory tracking task를 완수하는 differential drive robot을 안내한다.
6. Future directions
이번 section에서는 현재연구의 한계와 향상을 결론짓고 robot visual servo에서 learning based control scheme에 대한 미래연구방향을 논의한다. 공인된 control method의 장단점을 보여주는 비교 table이 주어지고(Table 2), 기존 알고리즘과 적용 시나리오의 단점에 따라 4가지 연구방향이 서술된다.
6.1. Adaptive NNs for robotic visual servo
NN-MPC가 robotic VS에 적용될 때, NN을 train하기 위해서 data를 얻는 것은 필수적이다. 그러나 대부분 neuron의 weight와 구조에 대한 tuning 방법은 경험적이고, 설계자는 설계된 NN의 hyper parameter가 특정 VS에 적합한지 하닌지 미리 깨달을 수 없다. 반면 RL측면에서, DNN이 value functions이나 policy의 parameter를 추정하는데 사용된다면, DNN을 설계하는 역할을 제공하는 것은 매우 중요하다. Han et al.는 training동안 구조와 parameter를 동시에 조정하는 radial basis function을 가진 self-organizing RNN을 제안한다. 그러므로, 유망한 방향은 adaptive algorithm을 통해 task에 적절하게 맞는 layer와 neuron의 수를 조절하는 방법을 찾는 것이다.
6.2. Safe control
RL이 policy를 online으로 최적화할 수 있음에도 불구하고, 이것의 learning process는 trial and error 프로세스이다. 이 process에서, robots은 피해나 사상자를 내는 극단적인 action을 취할 수 있다. 의료나 수술같은 몇몇 경우에, safety는 최우선순위이다. 그러므로, 효과적이고 안전하게 robotic VS로 learning 알고리즘을 도입하는 것은 유망한 연구주제이다. 몇몇 학자는 MPC에 Gaussian process regression을 결합하려고 시도했고, 로봇의 uncertain part가 더 작은 variance를 갖도록 근사하는 learning process(이는 특정 safety를 보장한다.)를 안내했다. 추가로, MPC를 위한 safe learning control이 논의되었다. 이는 특성 규모의 safety를 보장하는 robotic VS시스템을 위한 이론적 지지를 제공한다.
6.3. Model-free MPC
이 survey는 일부 model free방법인 model learning 방법을 위한 NN을 사용하는 것에 대한 현재 연구에 대해 논의하고 결론짓는다. VS시스템을 위해 가능한 연산량이 적고 다루기쉽고 완전한 model-free MPC를 만드는 것은 매우 중요하다. 그러나 기존의 model-free predictive controller는 보통 믿을 수 있는 dataset이 필요하고 시스템 model을 알기위해서 복잡한 nonconvex 최적화를 이용하고 있다.
6.4. Visual servo with multi-robot cooperation
대부분의 learning algorithms은 단일 로봇을 갖는 system에서 작동하는 것에 초점을 맞춘다. 약간의 연구들은 multi-robot systems [97]과 결합한다. 각각의 robot을 위한 효과적인 controller를 설계하는 것에 더해, 이런 로봇들사이에서 협력 또한 고려되어야 한다. learning-based control scheme을 multi-robot VS시스템에 적용하여 각각의 로봇이 neighbor의 정보를 얻기위한 카메라를 사용할 수 있고 복잡한 협력이나 대립작업을 완수하기 위한 지능적인 결정을 할 수 있게 하는 방법은 매우 유망한 주제이다.
6.5. Visual servo with human-Robot collaboration
인간-로봇 collaboration이나 human-in-loop 시스템은 일반적으로 인간과 로봇의 cooperation을 나타낸다. 이는 반복적이고 위함한 작업을 하는 인류를 대신해서 작업효율을 향상하고 고강도와 고정밀작업을 완수할 수 있다. review [98]에서, human gestures에 대한 recognition 기술이 매우 정교해졌다. 인간-로봇 collaboration에서 존재하는 일반적인 문제는 [99]에 소개되었다. 그러나 VS시스템에서 human factor를 계산에 넣는 것은 여전히 성숙한 것에서 거리가 멀다. 인간 의도에 따라 지능적인 결정을 하도록 로봇을 안내하는 learning 알고리즘이 거의 없기때문이다. learning-based 알고리즘을 그런 시나리오에 적용하는 것은 로봇이 인간의 의도와 행동을 인지하고 그들의 control 전략을 조정할 수 있도록 만들 수 있다. 이것은 인간-로봇 협력에서 VS 연구에 있어 매우 중요하다.
7. Conclusion
이 survey는 결론적으로 robotic VS시스템에 대한 learning-based 알고리즘을 자세히 말했다. 하나는 NN을 결합하고 나머지는 RL을 결합한다. sota 알고리즘은 unknown depth, unknown dynamics, constrained 최적화와 환경과의 상호작용의 어려움에 측면에서 robotics visual servo의 문제 해결에 큰 성공을 달성했다. 요컨대, 각기다른 분류를 각기다른 시나리오에 적용한다. 환경에 높은 요구를 갖는 시나리오는 learning 알고리즘이 지배하는 것이 필요하다. 반대로 MPC같은 전통적인 알고리즘은 더 많은 control 효과가 로봇 modeling에 높은 confidence와 더 적은 disturbance를 갖는 시나리오에서 특정 stability를 보장하는 것이 필요하다. AI와 전통적인 알고리즘의 개발은 learning based 알고리즘의 발전을 촉진할 수 있다. 이 survey는 controller들이 수렴성 and/or staility를 만족한다는 가정하에 모든 control scheme을 논한다는 것에 주의해라. 우리는 visual servoing task를 수행할 때, 각 control scheme의 특성을 고려하지않는다. 그것은 각 control scheme의 효과를 보장하기위한 실제 적용에 필수적이만.